

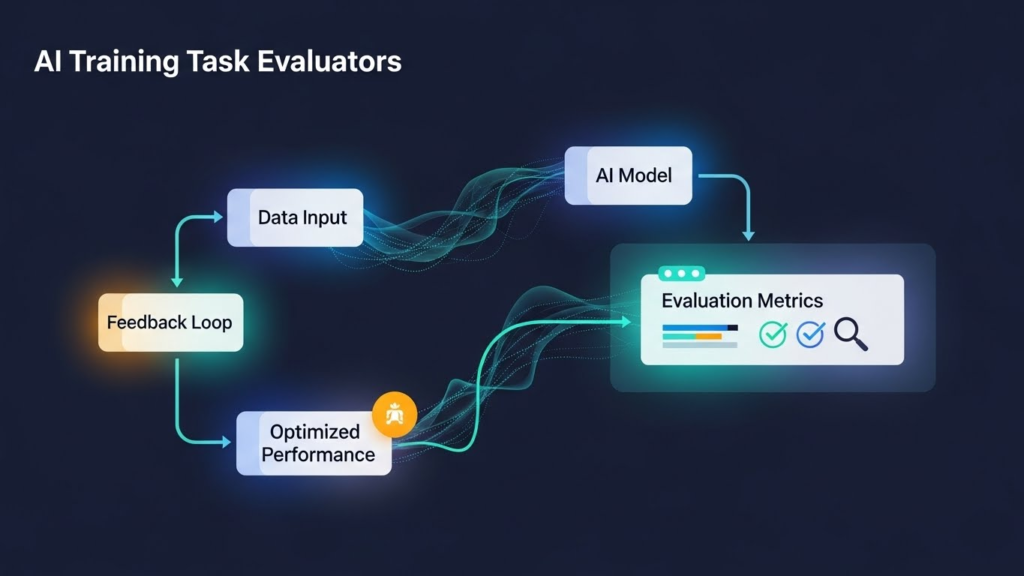
Artificial Intelligence (AI) models are only as good as the data and feedback that shape them. This is where AI training task evaluators play a crucial role. By meticulously reviewing and assessing AI outputs, these evaluators ensure that models learn from accurate, relevant, and high-quality information. Their work helps AI systems understand context better, avoid errors, and make predictions that are not only precise but also aligned with real-world expectations.
Beyond error correction, AI training task evaluators provide continuous guidance that allows models to adapt and improve over time. Their insights help fine-tune algorithms, identify biases, and enhance overall performance, making AI smarter and more reliable. In essence, these evaluators act as the bridge between raw AI capabilities and practical, trustworthy results, ensuring that models don’t just function, but truly perform at their best.
What Are AI Training Task Evaluators?
AI training task evaluators are systems or processes designed to assess, validate, and improve the training data and outputs of AI models. Their primary goal is to ensure that AI algorithms learn from high-quality, accurate, and unbiased data.
These evaluators can be:
- Human-in-the-loop evaluators – where human experts assess AI outputs and provide corrections.
- Automated evaluators – algorithms that automatically score or validate model outputs based on predefined metrics.
By continuously reviewing AI performance during training, evaluators identify errors, biases, and inconsistencies, which helps in fine-tuning the model for better results.
Why Model Accuracy Matters
Before diving into how evaluators improve AI, it’s essential to understand why accuracy is critical. Model accuracy directly affects:
- Decision-making – AI applications in healthcare, finance, and security rely on precise predictions.
- User trust – Low accuracy can erode confidence in AI systems.
- Business outcomes – Errors in AI can result in financial loss or reputational damage.
An inaccurate model is not just inefficient; it can actively harm an organization’s credibility and performance. This is why integrating robust evaluation mechanisms into AI training is non-negotiable.
How AI Training Task Evaluators Work

AI training task evaluators improve model accuracy through systematic assessment and iterative feedback loops. The key processes include:
1. Data Quality Assessment
Data is the foundation of any AI model. Evaluators ensure that:
- Training data is accurate, relevant, and balanced.
- Data sets cover edge cases to reduce bias.
- Outliers or errors are identified and corrected before feeding into the model.
Example: A sentiment analysis AI trained on customer reviews may misclassify sarcasm unless evaluators flag such examples for correction. You can see how remote online evaluators manage data accuracy
2. Model Output Validation
Evaluators monitor AI outputs to check whether predictions align with expected outcomes.
- Human evaluators may review chatbot responses or translation outputs for context accuracy.
- Automated systems calculate performance metrics like precision, recall, and F1 score to quantify accuracy.
3. Feedback Loops
The most effective evaluators use feedback loops to inform model adjustments.
- Errors detected by evaluators are fed back into the training process.
- Models are fine-tuned using corrected examples to reduce future mistakes.
This iterative approach ensures that models learn continuously and improve accuracy over time.
Types of AI Training Task Evaluators

Different AI applications require specialized evaluators. Understanding the types can help organizations implement the right strategy:
Human-in-the-Loop
- Combines human judgment with machine learning.
- Humans review AI outputs, providing corrections or annotations.
- Useful in areas requiring contextual understanding, like content moderation or medical diagnoses.
Automated Evaluators
- Use algorithms to assess performance metrics.
- Ideal for high-volume tasks where human evaluation is impractical.
- Can detect patterns, inconsistencies, and deviations from expected behavior.
Hybrid Evaluators
- Combine human and automated methods for optimal results.
- Provides scalable yet context-aware evaluation, suitable for complex AI systems.
Practical Benefits of Using AI Training Task Evaluators
Higher model accuracy
AI training task evaluators help identify mistakes and inconsistencies in model outputs during the training phase. By correcting these errors early, the AI learns more effectively from accurate data. This results in more precise predictions and a model that performs reliably in real-world scenarios.
Reduced bias
AI training task evaluators help identify and correct biased patterns in both data and model outputs. By ensuring diverse and representative datasets, they prevent the AI from making unfair or skewed predictions. This leads to more ethical, balanced, and trustworthy AI systems.
Improved reliability
Means that AI models consistently deliver accurate results across different tasks and scenarios. By continuously monitoring outputs and correcting errors, evaluators ensure the model performs dependably over time. This consistency builds trust in the AI system for both users and stakeholders.
Faster model improvement
Occurs because AI training task evaluators provide continuous feedback on errors and inaccuracies. By feeding these corrections back into the training process, models learn from their mistakes more quickly. This iterative approach accelerates the learning cycle, allowing AI systems to become more accurate and reliable in less time.
Implementing AI Training Task Evaluators Effectively

To maximize their benefits, organizations should adopt best practices for evaluator integration:
1. Define Clear Evaluation Metrics
- Use precision, recall, and F1 scores for performance measurement.
- Set benchmarks for acceptable error rates.
2. Use Diverse and High-Quality Data
- Include varied scenarios and edge cases.
- Avoid data that may introduce systemic bias.
3. Integrate Feedback Loops
- Ensure error corrections feed back into training cycles.
- Automate where possible for faster iterations.
4. Balance Human and Automated Evaluation
- Human evaluators for contextual and qualitative feedback.
- Automated evaluators for volume and quantitative scoring.
See how to choose the best online job reviewer for tips on integrating evaluators in practice
Challenges in AI Evaluation and How to Overcome Them
While AI training task evaluators are essential, implementing them comes with challenges:
1. Scaling Human Evaluation
- Problem: Manual review is resource-intensive.
- Solution: Use HITL for complex cases and automated evaluators for high-volume tasks.
2. Handling Biased Training Data
- Problem: Poor-quality data can reinforce biases.
- Solution: Regular audits of datasets and inclusion of diverse scenarios.
3. Maintaining Consistent Metrics
- Problem: Different teams may use varied evaluation criteria.
- Solution: Standardize metrics and document evaluation processes.
4. Real-Time Feedback Integration
- Problem: Feedback loops can slow down training if not automated.
- Solution: Implement automated pipelines for error detection and correction.
Future Trends in AI Evaluation
The purpose of AI evaluation is not just to measure a model’s accuracy, but also to assess its decision-making, fairness, robustness, and real-world applicability. In the future, AI evaluation is expected to become more dynamic and automated, using continuous feedback loops and real-time monitoring to constantly refine models. This trend is particularly important for generative AI and complex multimodal models, where traditional static testing methods are no longer sufficient.
Another key trend is toward explainability and transparency. Organizations will increasingly evaluate not only a model’s performance but also its reasoning process and bias mitigation. AI evaluation tools are becoming more human-aligned and interpretive, helping stakeholders understand model decisions and build trust. Additionally, cross-domain evaluation and collaborative benchmarking platforms will gain popularity, allowing multiple organizations and research groups to assess models using standardized frameworks.
Conclusion
AI training task evaluators play a pivotal role in enhancing model accuracy by systematically reviewing, scoring, and refining AI outputs. Their insights help identify patterns of errors, biases, or inconsistencies that automated systems alone might overlook. By providing high-quality human feedback, evaluators guide models to better understand context, nuance, and user intent, which directly improves performance across tasks and applications.
Moreover, integrating AI training task evaluators into the development cycle ensures continuous improvement and adaptability. As AI models evolve, evaluators help maintain alignment with real-world expectations, ethical standards, and domain-specific requirements. This combination of human oversight and machine learning not only boosts accuracy but also builds trust in AI systems, making them more reliable, effective, and user-centric over time.
FAQs
1. What is an AI training task evaluator?
An AI training task evaluator is a professional or automated system that reviews and assesses AI-generated outputs during the training process. Their role is to ensure that the model’s responses are accurate, relevant, and aligned with the intended objectives.
2. How do AI training task evaluators improve model accuracy?
They improve accuracy by identifying errors, biases, and inconsistencies in the AI’s responses. Feedback from evaluators is used to refine training data, adjust algorithms, and optimize model behavior for better performance.
3. Why is human evaluation important in AI training?
Human evaluation ensures that AI outputs are contextually correct, ethical, and aligned with real-world expectations. While automated metrics can measure performance, humans provide nuanced insights that machines might miss.
4. Can AI training task evaluators detect bias in AI models?
Yes. Evaluators can spot biased outputs, unfair assumptions, or underrepresented perspectives in AI responses. This helps in retraining the model with balanced and inclusive data.
5. How often should AI models be evaluated by task evaluators?
Evaluation should be continuous or iterative, especially during major updates or when the model encounters new types of data. Regular assessment ensures the model remains accurate and reliable over time.
6. What tools do AI training task evaluators use?
Evaluators use a combination of annotation platforms, performance dashboards, automated scoring systems, and manual review processes to assess AI outputs effectively.
7. Is AI training task evaluation only for large AI models?
No. Evaluation is crucial for AI models of all sizes, from small specialized models to large-scale general-purpose models, because accuracy and reliability are important at every level.

